RAG
Large language models (LLMs) are trained on public data and have a training cutoff date, so they aren’t inherently aware of private or the latest information. As a result, LLMs may not have the necessary information to answer a user’s question, even though they might pretend to (a.k.a. hallucinate). This is a common problem, especially in an enterprise setting, where the information is proprietary and/or constantly changing. Unfortunately, this is also an environment where plausible but inaccurate answers can have serious consequences.
There are roughly three general approaches to addressing this problem, going from the least to most complex:
- System prompt: If the information that the model needs to perform well can fit within a system prompt (i.e., fit within the relevant context window), you should consider that first.
- Tool calling: Provide the LLM with tools it can use to retrieve the information that it needs. Compared to RAG, this has the benefit of not needing to pre-fetch/maintain an information database, compute document/query similarities, and can even be combined with RAG.
- Retrieval-Augmented Generation (RAG): Among these options, this can be the most demanding to implement and maintain, but also offers the most control over when and how exactly the LLM gains access to the information it needs.
If RAG sounds right for your use case, the next section gives a basic example of how to implement it using Shiny and chatlas. The last section provides some tips on how to scale up your RAG implementation.
RAG basics
The core concept of RAG is fairly simple, yet general: given a set of documents and a user query, find the document(s) that are the most similar to the query and supply those documents as additional context to the LLM. This requires choosing a numerical technique to compute similarity, of which there are many, each with its own strengths and weaknesses. The often tricky part of doing RAG well is finding the similarity measure that is both performant and effective for your use case.
To demonstrate, let’s use a basic example derived from chatlas’s article on RAG. The main idea is to implement a function (get_top_k_similar_documents) that finds the top-k most similar documents to a user query. Note that similarity depends on two main factors:
- The embedding model (for embedding text into a numerical vector space).
- Here we use the popular
all-MiniLM-L12-v2model, which offers a nice balance between performance and speed.
- The similarity metric (for computing similarity between two vectors).
- Here we use cosine similarity, which is a common choice for text embeddings.
rag.py
import numpy as np
from sentence_transformers import SentenceTransformer
embed_model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
# A list of 'documents' (one document per list element)
documents = [
"The unicorn programming language was created by Horsey McHorseface.",
"It's known for its magical syntax and rainbow-colored variables.",
"Unicorn is a dynamically typed language with a focus on readability.",
"Some other programming languages include Python, Java, and C++.",
"Some other useless context...",
]
# Compute embeddings for each document (do this once for performance reasons)
embeddings = [embed_model.encode([doc])[0] for doc in documents]
def get_top_k_similar_documents(user_query, top_k=3):
# Compute embedding for the user query
query_embedding = embed_model.encode([user_query])[0]
# Calculate cosine similarity between the query and each document
similarities = np.dot(embeddings, query_embedding) / (
np.linalg.norm(embeddings, axis=1) * np.linalg.norm(query_embedding)
)
# Get the top-k most similar documents
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [documents[i] for i in top_indices]app.py
from chatlas import ChatAnthropic
from rag import get_top_k_similar_documents
from shiny.express import ui
chat_client = ChatAnthropic(
model="claude-3-7-sonnet-latest",
system_prompt="""
You are a helpful AI assistant. Using the provided context,
answer the user's question. If you cannot answer the question based on the
context, say so.
""",
)
chat = ui.Chat(
id="chat",
messages=["Hello! How can I help you today?"],
)
chat.ui()
chat.update_user_input(value="Who created the unicorn language?")
@chat.on_user_submit
async def _(user_input: str):
top_docs = get_top_k_similar_documents(user_input, top_k=3)
prompt = f"Context: {top_docs}\nQuestion: {user_input}"
response = await chat_client.stream_async(prompt)
await chat.append_message_stream(response)
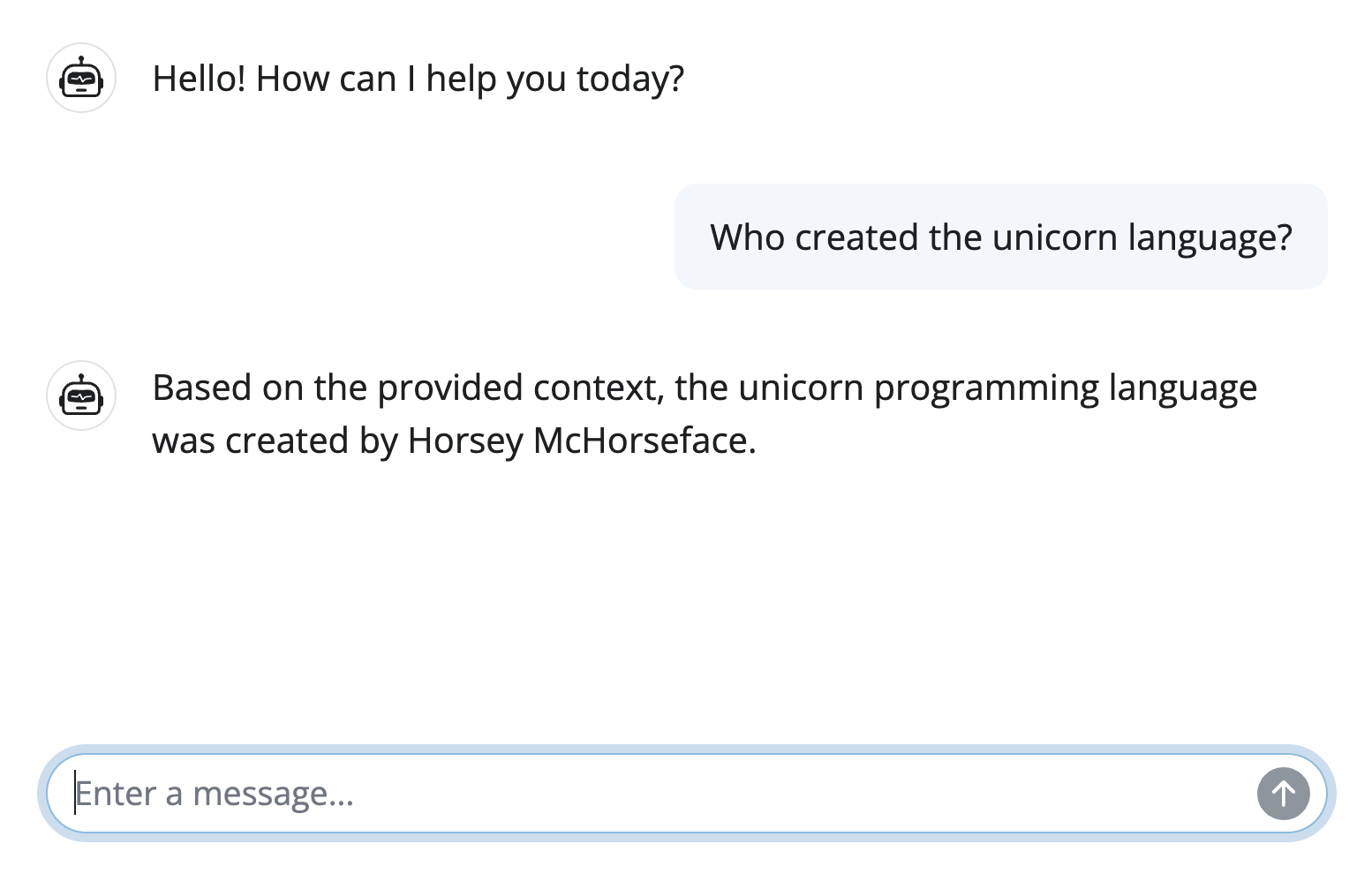
Scaling up
To scale this basic example up to your use case, you’ll not only want to consider an embedding model and similarity metric that better matches your use case, but also a more efficient way to store/retrieve your documents.
Nowadays, there are many options for efficient storage/retrieval of documents (i.e., vector databases). That said, duckdb’s vector extension comes highly recommended, and here is a great blog post on building a database and retrieving from it with a custom embedding model. Many of these options will offer both a local and cloud-based solution, so you can choose the one that best fits your needs. For example, with duckdb, you can leverage MotherDuck for your hosting needs, as well as others like Pinecone and Weaviate.