Unicode characters in Shiny apps
Since Shiny v0.10.1, we have added support for multi-byte characters in Shiny apps on Windows. Linux and Mac OS X users normally do not need to worry about character encodings or non-ASCII characters, and they can basically ignore this article, since their system locale is often UTF-8 based. However, Windows does not have a single consistent locale or native character encoding, which makes it tricky to support multi-byte characters there. For the sake of consistency and portability, Shiny requires the character encoding of all its components to be UTF-8, which include ui.R, server.R, global.R, DESCRIPTION, and/or README.md. Note a Shiny app may not contain all of these files, but all of them must be encoded in UTF-8 if they exist.
Text Editors
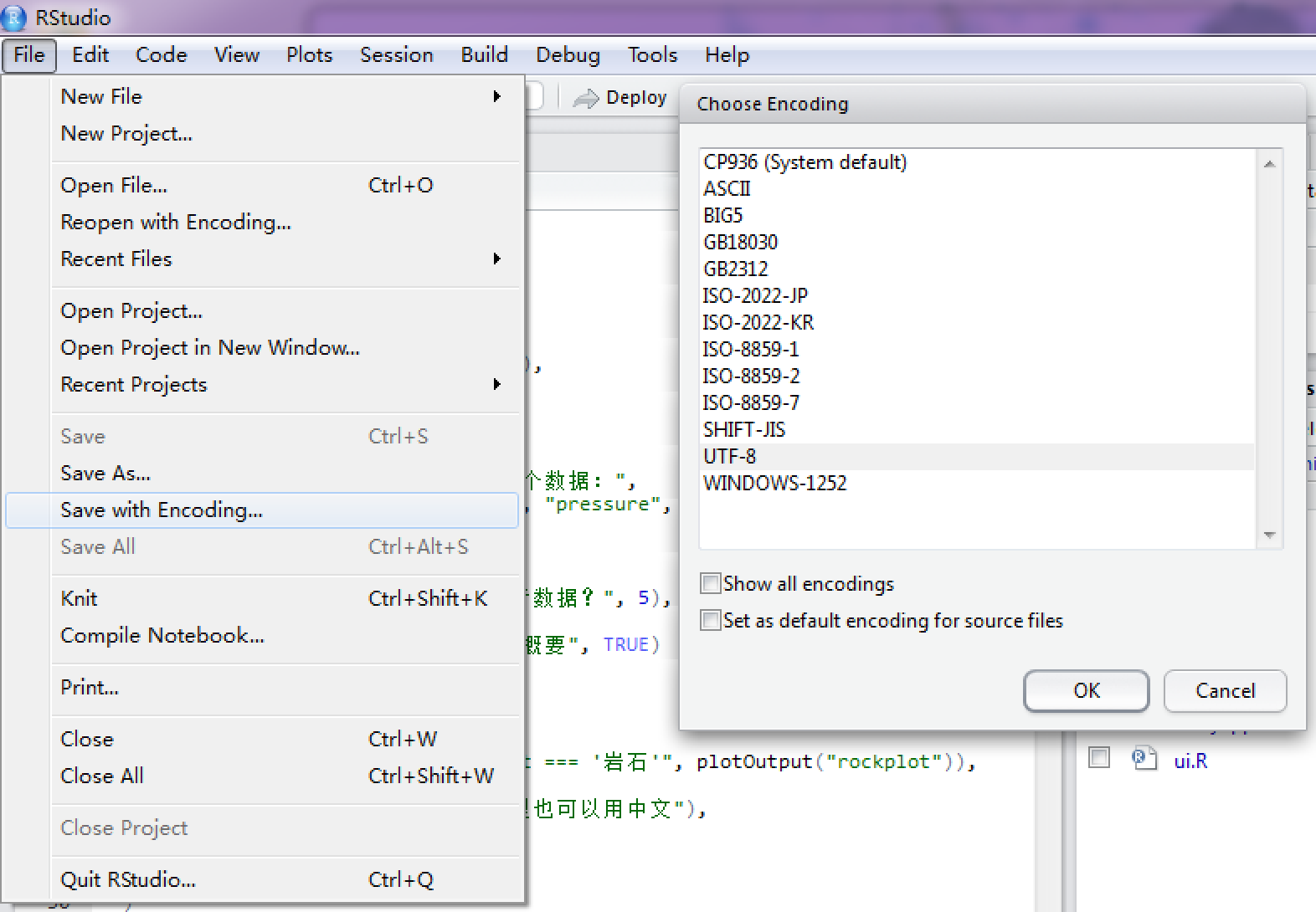
A modern text editor should allow you to save a text file with a specified encoding. For example, if you use the RStudio IDE, you can click the menu File -> Save with Encoding to (re)save a file with the UTF-8 encoding:
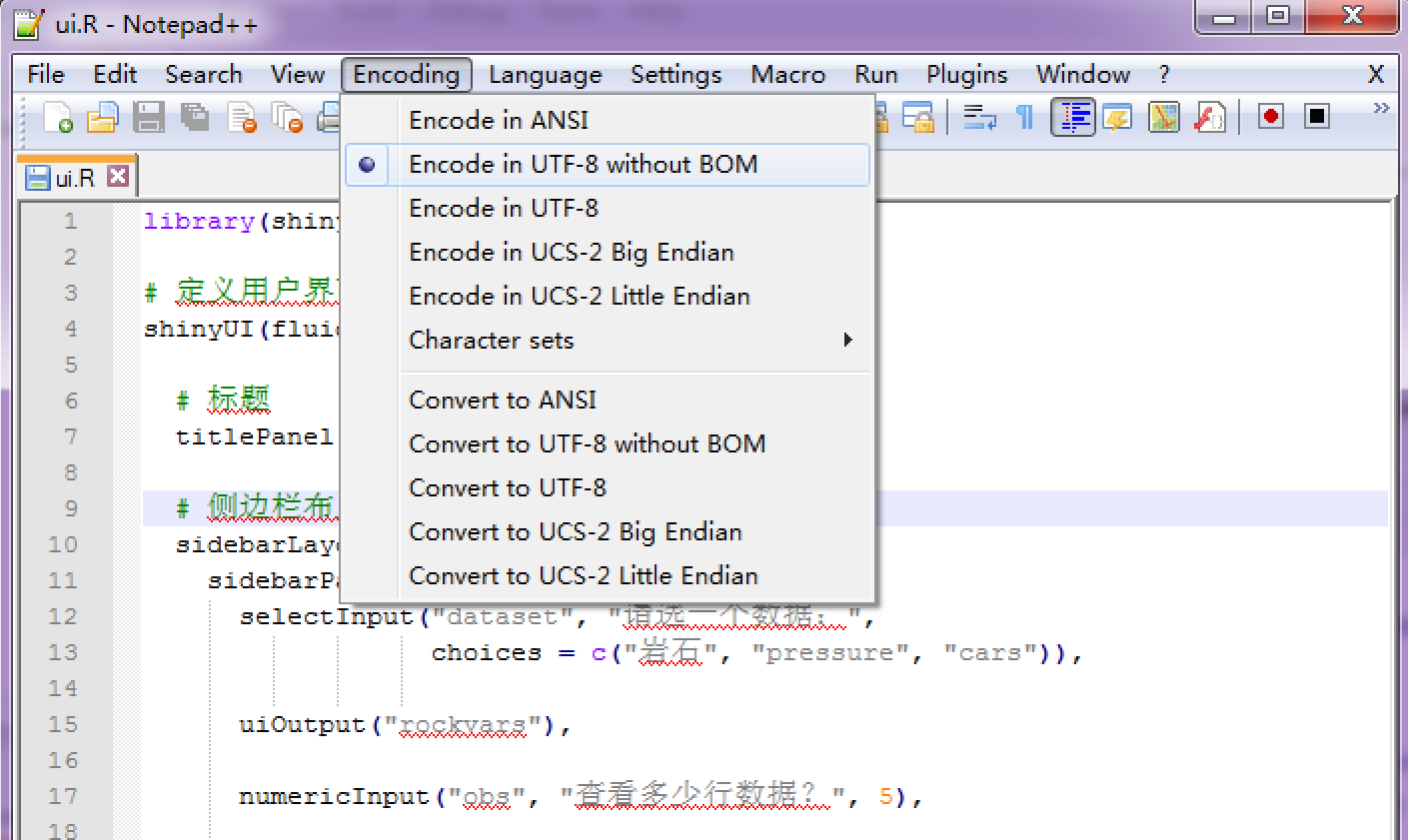
If you do not use RStudio, there is one more thing to keep in mind: when you save a file with UTF-8, you should make sure not to include the byte order mark (BOM). Some text editors do include it by default, such as Notepad (the default text editor on Windows). Shiny will try to detect the BOM character, and give a warning if it exists. For a file that is encoded in UTF-8 with BOM, you can open it with the UTF-8 encoding in RStudio, re-save it with the UTF-8 encoding, and the BOM will be removed. There are many other text editors that support UTF-8 with or without BOM, such as Notepad++:
An Example (Chinese Characters)
There is an example in the gallery demonstrating Simplified Chinese characters in a Shiny app, in which we used Chinese characters in many places, such as R comments, the title of the page, the label and choices of the select input, the JavaScript condition of the conditional panel, the id of the verbatim text output, the R formula, and so on.
File Input/Output
When your Shiny app involves file input/output, the character encoding does not have to be UTF-8. Although we recommend UTF-8 in Shiny, it is not the default encoding on Windows anyway, so your app users may have trouble especially when they have file interactions with your app.
Many I/O functions in R have an argument named encoding (sometimes fileEncoding). If the data to be read or written is not encoded with the native encoding of your system, you may have to use the encoding argument. For example, when reading a text file encoded in UTF-8 into a Shiny app, you may use readLines('foo.txt', encoding = 'UTF-8'). Similarly, when writing a CSV file with the GB2312 encoding (a commonly used encoding for Simplified Chinese), you can use write.csv(data, fileEncoding = 'GB2312'). This is very important when using the fileInput() or downloadHandler() functions in the shiny package.
If you read a file into R as a character vector, and the file is not encoded with your system’s native encoding, you are recommended to convert the encoding of the character vector to your system’s native encoding before you process the text data. Some character string processing functions such as gsub(..., fixed = TRUE) may not work if the string does not have the native encoding.
x <- readLines('foo.txt', encoding = 'UTF-8')
x <- enc2native(x)
gsub(' ', '-', x, fixed = TRUE)The Global encoding Option
The function options() in base R can be used to set some global options for the current R session, among which there is an encoding option. Its default value is native.enc (native encoding), which is not really a standard encoding name, and its meaning differs on different platforms. On Linux and Mac OS X, the native encoding is often UTF-8. If you are not sure what your native encoding is, the function localeToCharset() in base R should give a reasonable guess in most cases.
When dealing with encoding problems, you are not recommended to set the encoding option to a specific encoding name, e.g. options(encoding = 'UTF-8'). This may have very bad consequences, since it makes a strong assumption that all file connections and character manipulations should use this encoding by default.
Shinyapps.io
For shinyapps.io users, the platform is based on Linux containers, and has a UTF-8 locale. If your app reads/writes data files that contain multi-byte characters, you are strongly recommended to be specific about the encodings when calling the I/O functions, because your local environment may not be based on UTF-8. The functions iconv(), iconvlist(), enc2native(), and enc2utf8() may be useful if you need to convert the encoding from one to another.
Summary
To sum up, three things to keep in mind when dealing with character strings in R:
- The encoding should be specified explicitly per (file) connection basis, if you want your R code to be portable;
- After you read Unicode characters into R, convert them to the native encoding of your system, e.g. using
enc2native(); - Do not set
options(encoding).